Retrieval Augmented Generation (RAG) with Amazon OpenSearch Vector DB & Langchain
Tags: blog, openai, chatgpt, vectordb, software, langchain, python, rag

One of the more tangible usecases of Generative AI of late has been the ability to vector-encode various texts, and run queries on them - most often as a very effective knowledgebase search.
The technique du jour is something called RAG (Retrieval Augmented Generation) - essentially, take a user’s query, retrieve the most relevant text from a large knowledge base, and pass the text plus the original question to an LLM, asking it to phrase an answer.
At the heart of these RAG-based solutions is a vector database to store documents in. The poster child of the space is an a16z-backed company called PineCone, but it’s a standalone SaaS service, which for a database, doesn’t meet the needs of the many enterprise customers I work with.
Amazon have just launched a version of OpenSearch’s Vector Database, which is serverless - so there’s no need to worry about infrastructure. In this post, I will show how to pair it with Langchain to quickly set up a RAG-based solution.
My programming language of choice is typically Javascript - but alas the Javascript bindings for Langchain at time of writing don’t support AWS hosted instances of OpenSearch VectorDB - so we’re going to have to use Python.
Create an Opensearch Serverless Vector Collection
Use the Easy create wizard in the UI, give your collection a name, and be sure to pick Vector search as the collection type.
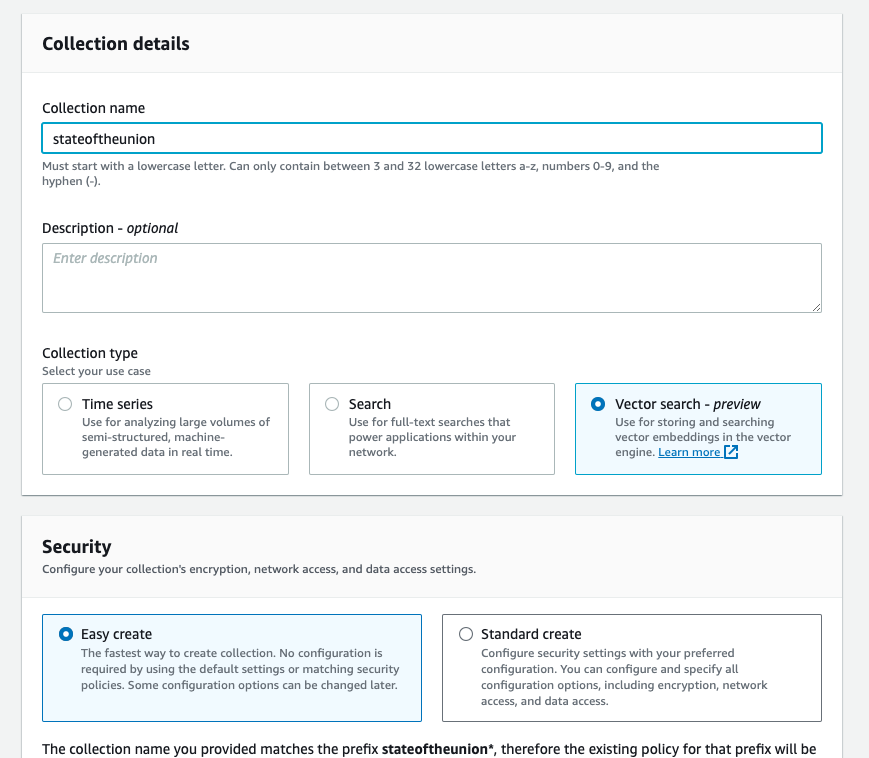 After creation, take note of the “Opensearch Endpoint” url. As of right now, the AWS console doesn’t really support index creation/maintinence in any meaningful way, so we’ll do this through the command line.
After creation, take note of the “Opensearch Endpoint” url. As of right now, the AWS console doesn’t really support index creation/maintinence in any meaningful way, so we’ll do this through the command line.
Dependencies
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import OpenSearchVectorSearch
from langchain.document_loaders import TextLoader
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
Setting up AWS4 Authentication & OpenSearch Client
All requests to OpenSearch are AWS4 authenticated - the inner workings of this are beyond what I’m trying to illustrate here, so I’m assuming a working knowledge of AWS IAM. Get your credentials through an IAM user, SSO, or whatever your preferred method is.
# Configuration
host = 'ab1c2de3fghi4jklmnop.eu-west-1.aoss.amazonaws.com' # NB without HTTPS prefix, without a port - be sure to substitute your region again
region = 'eu-west-1' # substitute your region here
service = 'aoss'
credentials = boto3.Session().get_credentials()
auth = AWSV4SignerAuth(credentials, region, service)
client = OpenSearch(
hosts=[{'host': host, 'port': 443}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
Pick an embeddings algorithm
When picking an embeddings model, the dimensions output by the model are important to consider - the vector database index we create needs to know this count. The two options I’ve explored are:
- OpenAI’s
text-embedding-ada-002- 1536 dimensions BAII/bge-large-enfrom Huggingface - 1024 dimensions
The easiest option is to use OpenAI’s embeddings model (text-embedding-ada-002), as the embeddnigs are computed by OpenAI’s hosted inference endpoints, and run much faster:
# Embeddings
embeddings = OpenAIEmbeddings()
dimensions = 1536
OR: If you instead want to use BGE embeddings, use this code instead:
from langchain.embeddings import HuggingFaceEmbeddings
# create HuggingFaceEmbeddings with BGE embeddings
model_name = "BAAI/bge-large-en"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
mbeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
dimensions = 1024
Create an Index in the Opensearch Vector DB
Now, we’ll need to create an index in the AWS Serverless Vector DB:
# Index Creation
index_name = "stateunion"
indexBody = {
"settings": {
"index.knn": True
},
"mappings": {
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": dimensions,
"method": {
"engine": "faiss",
"name": "hnsw"
}
}
}
}
}
try:
create_response = client.indices.create(index_name, body=indexBody)
print('\nCreating index:')
print(create_response)
except Exception as e:
print(e)
print("(Index likely already exists?)")
Index and split the text
We’re going to index a text, the State of the Union address - you can grab it from here: https://gist.github.com/cianclarke/b85a86a9a1871df8ebb998fa197db470#file-stateoftheunion-txt
# Index Documents
loader = TextLoader("./stateoftheunion.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
docsearch = OpenSearchVectorSearch.from_documents(
docs,
embeddings,
opensearch_url=f'https://{host}:443',
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
index_name=index_name
)
Search for your document in the VectorDB
Now, let’s define our query, and search for the closest match in the vector DB to our query.
docsearch = OpenSearchVectorSearch.from_documents(
docs,
embeddings,
opensearch_url=f'https://{host}:443',
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
index_name=index_name
)
# Document Search
query = "What is happening with Justice Breyer"
docs = docsearch.similarity_search(query, k=200)
print('Total results:', len(docs))
# The result here should be the document which closest resembles our question - the RAG phase actually formats an answer.
print('Best result:', docs[0].page_content)
In this example, the output of docsearch.similarity_search is purely to illustrate how to run encoded queries against the vector database, without the full chain of the RAG query.
Create a chain which performs basic RAG
Lastly, let’s make a LangChain chain, which constructs a prompt that has an answer the question based on provded context from our VectorDB.
# RAG Prompt
retriever = docsearch.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# The result here should be a well-formatted answer to our question
print(chain.invoke(query))
We should see the answer to our question: What is happening with Justice Breyer?
Justice Breyer is retiring from the United States Supreme Court
That’s it! A basic RAG pipeline using AWS’s serverless instance of OpenSearch Vector DB, combined with Langchain.